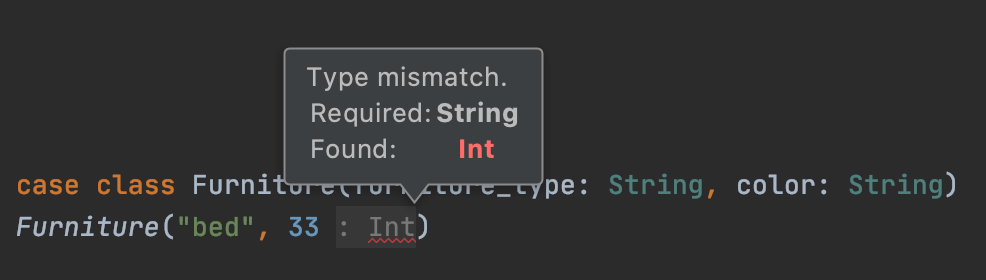
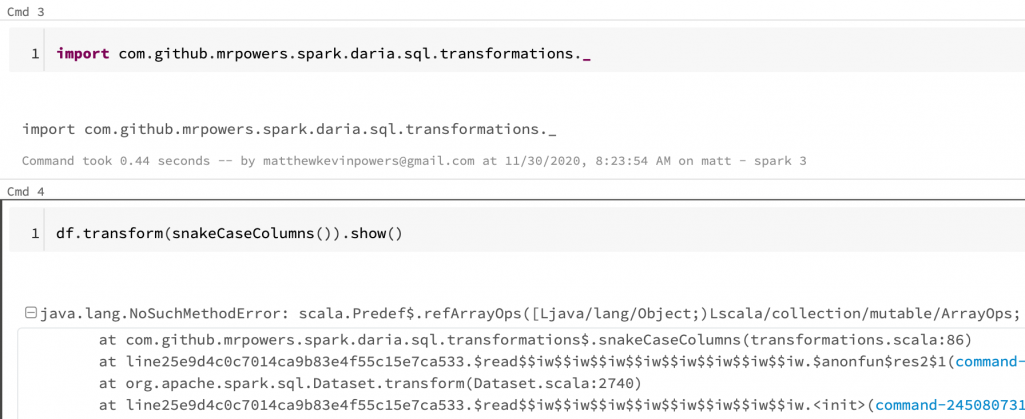
Convert streaming CSV data to Delta Lake with different latency requirements
This blog post explains how to incrementally convert streaming CSV data into Delta Lake with different latency requirements. A streaming CSV data source is used because it’s easy to demo, […]