The Virtuous Content Cycle for Developer Advocates
This post explains how to scale developer advocacy by creating content in a way that answers current user questions and makes it easier to generate additional content in the future. […]

This post explains how to scale developer advocacy by creating content in a way that answers current user questions and makes it easier to generate additional content in the future. […]
DevRel Driven Development is driving software development from developer advocacy activities like creating documentation, writing blog posts, and producing videos. Developers advocates frequently identify public interface warts when creating content. […]
This blog post explains how to incrementally convert streaming CSV data into Delta Lake with different latency requirements. A streaming CSV data source is used because it’s easy to demo, […]
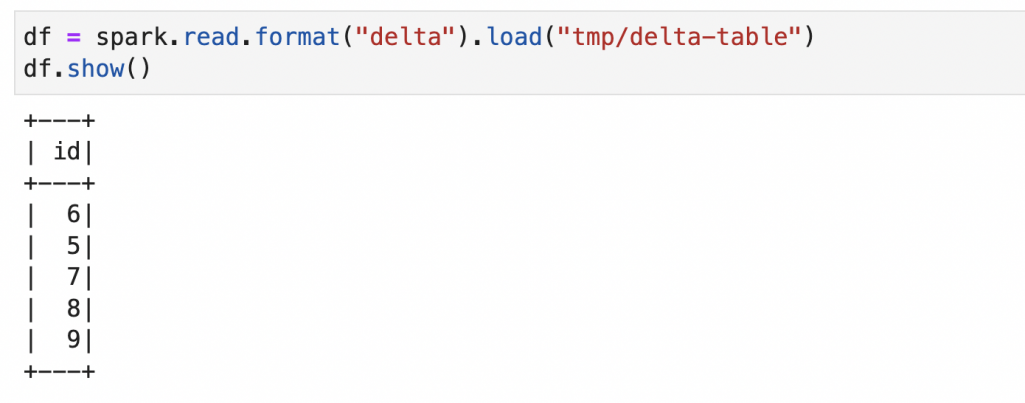
This blog post explains how to install PySpark, Delta Lake, and Jupyter Notebooks on a Mac. This setup will let you easily run Delta Lake computations on your local machine […]
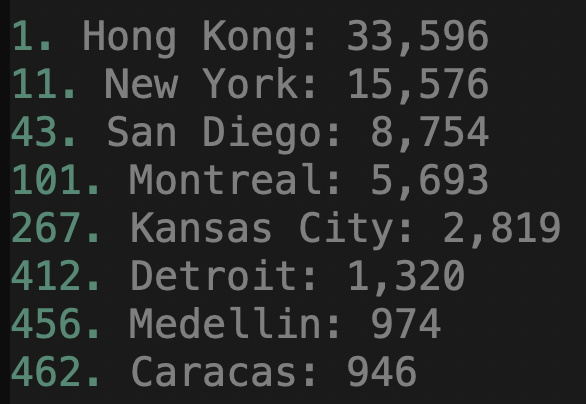
This post explains how to identify ultra-cheap international real estate markets and when you can capitalize on deeply discounted prices. Let’s borrow Andrew Henderson’s definition of an ultra-cheap real estate […]
This post explains how to read multiple CSVs into a pandas DataFrame. pandas filesystem APIs make it easy to load multiple files stored in a single directory or in nested […]
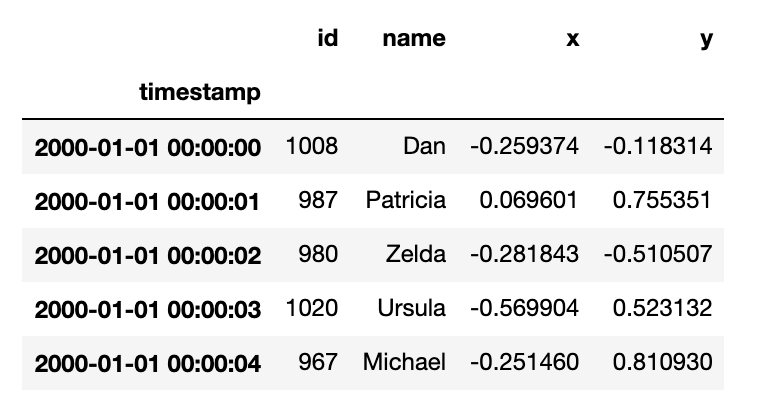
pandas is a great DataFrame library for datasets that fit comfortably in memory, but throws out of memory exceptions for datasets that are too large. This post shows how pandas […]
This post explains the different ways to save a NumPy array to text files. After showing the different syntax options the post will teach you some better ways to write […]
This post demonstrates how much money you can make as a content creator and contrasts the content creation and restaurant business models. Content creators can make a lot of money […]
This post explains how to read Delta Lakes into Dask DataFrames. It shows how you can leverage powerful data lake management features like time travel, versioned data, and schema evolution […]