exists and forall PySpark array functions
This blog post demonstrates how to find if any element in a PySpark array meets a condition with exists or if all elements in an array meet a condition with […]

This blog post demonstrates how to find if any element in a PySpark array meets a condition with exists or if all elements in an array meet a condition with […]
Passing a dictionary argument to a PySpark UDF is a powerful programming technique that’ll enable you to implement some complicated algorithms that scale. Broadcasting values and writing UDFs can be […]
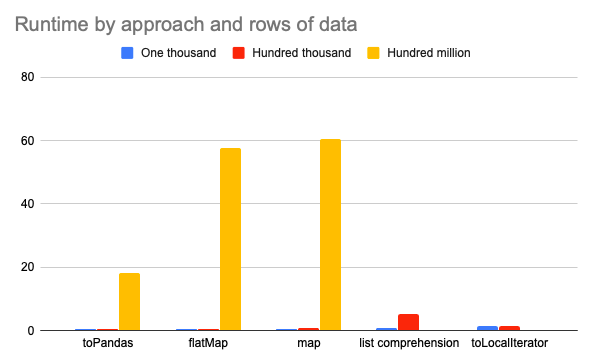
There are several ways to convert a PySpark DataFrame column to a Python list, but some approaches are much slower / likely to error out with OutOfMemory exceptions than others! […]
This post shows you how to fetch a random value from a PySpark array or from a set of columns. It’ll also show you how to add a column to […]
Dots / periods in PySpark column names need to be escaped with backticks which is tedious and error-prone. This blog post explains the errors and bugs you’re likely to see […]
Python dictionaries are stored in PySpark map columns (the pyspark.sql.types.MapType class). This blog post explains how to convert a map into multiple columns. You’ll want to break up a map […]
This blog post explains how to rename one or all of the columns in a PySpark DataFrame. You’ll often want to rename columns in a DataFrame. Here are some examples: […]
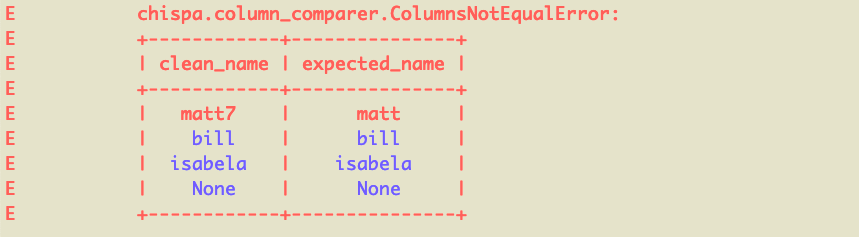
This blog post explains how to test PySpark code with the chispa helper library. Writing fast PySpark tests that provide your codebase with adequate coverage is surprisingly easy when you […]
This blog post explains how to create a PySpark project with Poetry, the best Python dependency management system. It’ll also explain how to package PySpark projects as wheel files, so […]
PySpark code should generally be organized as single purpose DataFrame transformations that can be chained together for production analyses (e.g. generating a datamart). This blog post demonstrates how to monkey […]