Creating an IT Ticketing System with GitHub and Slack
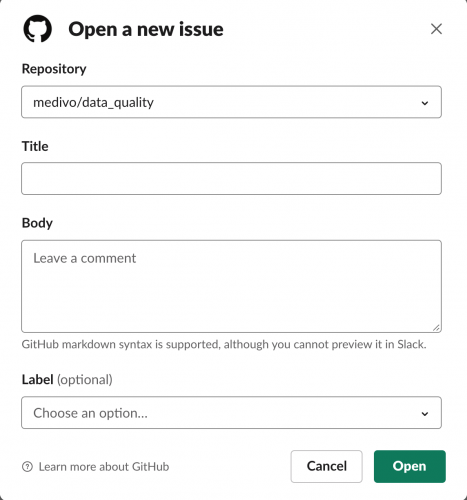
GitHub is great for an IT ticketing system – it’s easy to create issues, set assignees, and prioritize the ticket with labels. The GitHub Slack integration makes it easy to […]

GitHub is great for an IT ticketing system – it’s easy to create issues, set assignees, and prioritize the ticket with labels. The GitHub Slack integration makes it easy to […]
This blog post explains how to import core Spark and Scala libraries like spark-daria into your projects. It’s important for library developers to organize package namespaces so it’s easy for […]
Apache Spark is a big data engine that has quickly become one of the biggest distributed processing frameworks in the world. It’s used by all the big financial institutions and […]
This blog post explains how to use the HyperLogLog algorithm to perform fast count distinct operations. HyperLogLog sketches can be generated with spark-alchemy, loaded into Postgres databases, and queried with […]
Delta lakes prevent data with incompatible schema from being written, unlike Parquet lakes which allow for any data to get written. Let’s demonstrate how Parquet allows for files with incompatible […]
Delta makes it easy to update certain disk partitions with the replaceWhere option. Selectively applying updates to certain partitions isn’t always possible (sometimes the entire lake needs the update), but […]
Spark writers allow for data to be partitioned on disk with partitionBy. Some queries can run 50 to 100 times faster on a partitioned data lake, so partitioning is vital […]
This blog posts explains how to update a table column and perform upserts with the merge command. We explain how to use the merge command and what the command does […]
Delta lakes are versioned so you can easily revert to old versions of the data. In some instances, Delta lake needs to store multiple versions of the data to enable […]
This post explains how to compact small files in Delta lakes with Spark. Data lakes can accumulate a lot of small files, especially when they’re incrementally updated. Small files cause […]