Fetching Random Values from PySpark Arrays / Columns
This post shows you how to fetch a random value from a PySpark array or from a set of columns. It’ll also show you how to add a column to […]

This post shows you how to fetch a random value from a PySpark array or from a set of columns. It’ll also show you how to add a column to […]
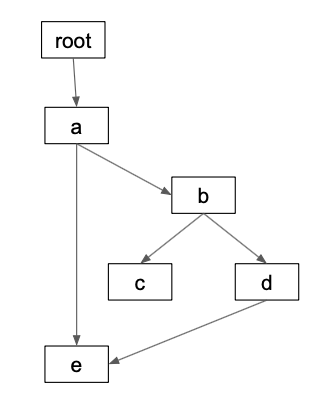
Directed Acyclic Graphs (DAGs) are a critical data structure for data science / data engineering workflows. DAGs are used extensively by popular projects like Apache Airflow and Apache Spark. This […]
Dots / periods in PySpark column names need to be escaped with backticks which is tedious and error-prone. This blog post explains the errors and bugs you’re likely to see […]
Python dictionaries are stored in PySpark map columns (the pyspark.sql.types.MapType class). This blog post explains how to convert a map into multiple columns. You’ll want to break up a map […]
This blog post explains how to rename one or all of the columns in a PySpark DataFrame. You’ll often want to rename columns in a DataFrame. Here are some examples: […]
This blog explains how to write out a DataFrame to a single file with Spark. It also describes how to write out data in a file with a specific name, […]
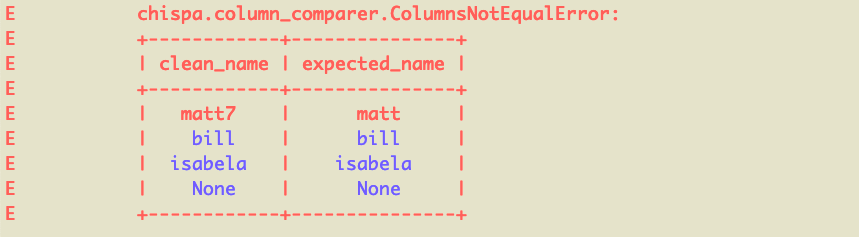
This blog post explains how to test PySpark code with the chispa helper library. Writing fast PySpark tests that provide your codebase with adequate coverage is surprisingly easy when you […]
This blog post explains how to create a PySpark project with Poetry, the best Python dependency management system. It’ll also explain how to package PySpark projects as wheel files, so […]

Adding executables to your PATH is fun, easy, and a great way to learn about how your machine works. This pattern is especially useful for long commands that you need […]
This blog post explains how to filter in Spark and discusses the vital factors to consider when filtering. Poorly executed filtering operations are a common bottleneck in Spark analyses. You […]