Scala Templates with Scalate, Mustache, and SSP
The scalate library makes it easy to use Mustache or SSP templates with Scala. This blog post will show how to use Mustache and SSP templates and compares the different […]

The scalate library makes it easy to use Mustache or SSP templates with Scala. This blog post will show how to use Mustache and SSP templates and compares the different […]
frameless is a great library for writing Datasets with expressive types. The library helps users write correct code with descriptive compile time errors instead of runtime errors with long stack […]
This blog post explains how to write sqlite tables to CSV and Parquet files. It’ll also show how to output SQL queries to CSV files. It’ll even show how to […]
This blog post demonstrates how to build a sqlite database from CSV files. Python is perfect language for this task because it has great libraries for sqlite and CSV DataFrames. […]

Poetry makes it easy to install Pandas and Jupyter to perform data analyses. Poetry is a robust dependency management system and makes it easy to make Python libraries accessible in […]
Metadata can be written to Parquet files or columns. This blog post explains how to write Parquet files with metadata using PyArrow. Here are some powerful features that Parquet files […]
The PyArrow library makes it easy to read the metadata associated with a Parquet file. This blog post shows you how to create a Parquet file with PyArrow and review […]
Dask is a great technology for converting CSV files to the Parquet format. Pandas is good for converting a single CSV file to Parquet, but Dask is better when dealing […]
Passing a dictionary argument to a PySpark UDF is a powerful programming technique that’ll enable you to implement some complicated algorithms that scale. Broadcasting values and writing UDFs can be […]
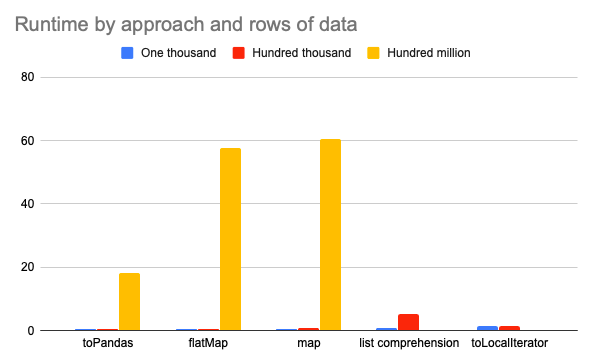
There are several ways to convert a PySpark DataFrame column to a Python list, but some approaches are much slower / likely to error out with OutOfMemory exceptions than others! […]